分词粒度
- 可分为word,sub-word,charlevel三个分词等级
- 其中word level存在以下问题:
- 超大的vocabulary size, 比如中文的常用词可以达到20W个
- 通常面临比较严重的OOV问题
- vocabulary 中存在很多相似的词
- charlevel存在以下问题:
- 文本序列会很长
- 无法对语义进行比较好的表征
- sub-word介于word和char之间,它不会对高频词汇进行分词,而是对低频词汇进行分词,是目前的主流方法
BPE(Byte Pair Encoding)
-
是一种sub-word的分词方法
-
步骤:
- 统计输入中所有出现的单词并在每个单词后加一个单词结束符 -> ['hello': 6, 'world': 8, 'peace': 2](避免一个词为另一个词的子词的情况)
- 将所有单词拆成单字 -> {'h': 6, 'e': 10, 'l': 20, 'o': 14, 'w': 8, 'r': 8, 'd': 8, 'p': 2, 'a': 2, 'c': 2, '': 3}
- 合并最频繁出现的单字(l, o) -> {'h': 6, 'e': 10, 'lo': 14, 'l': 6, 'w': 8, 'r': 8, 'd': 8, 'p': 2, 'a': 2, 'c': 2, '': 3}
- 合并最频繁出现的单字(lo, e) -> {'h': 6, 'lo': 4, 'loe': 10, 'l': 6, 'w': 8, 'r': 8, 'd': 8, 'p': 2, 'a': 2, 'c': 2, '': 3}
- 反复迭代直到满足停止条件
-
得到子词表后,对句子进行分词
-
在上述算法执行后,如果句子中仍然有子字符串没被替换但所有subword都已迭代完毕,则将剩余的子词替换为特殊token。原则上这个特殊的token出现的越少越好,往往用这个特殊token的数量来评价一个tokenizer的好坏程度,这个token出现的越少,tokenizer的效果往往越好
-
PS:由BPE算法的串行性可知,ifelse分支很多,GPU加速有限,很多时候进行tokenizing的时候,GPU util都是0
BBPE(Byte BPE)
- 使用BPE算法进行分词时,如果训练的语料不是英文,或者为特殊符号,则无法进行分词
- BBPE用比特构建最基础词表,将BPE的从字符级别扩展到子节(Byte)级别。在byte序列上使用BPE算法进行相邻合并,其核心思想是从字节开始,不断找词频最高、且连续的两个字节组合合并,直到达到目标词数。这样的方式可以更好地处理多语言文本和特殊字符。例如,在处理包含多种语言的文本时,传统的 BPE 可能会因为不同语言的字符编码差异而遇到问题,但BBPE以一个字节为一种 “字符”,不管实际字符集用了几个字节来表示一个字符
- 能够实现跨语言tokenize,但是似乎可能会导致乱码问题???(例如中文)
WordPiece
- wordpiece算法可以看作是BPE的变种。不同的是,WordPiece基于概率生成新的subword而不是下一最高频单字对,即对于子词A和B,观察它们合并之后的出现子词AB是否为常见情况,即下述指标越大越好:
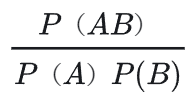
Unigram
- 不同于BPE和WordPiece,Unigram最大化句子被当前词表切分的总概率
- Unigram基于以下假设:一个句子是由若干个子词组成的,每个子词是独立生成的(即一元语言模型),目标是找到最大概率的子词组合方式:
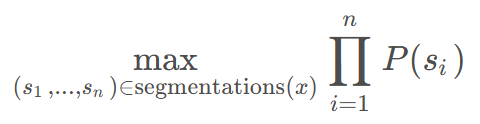
- 其中P(Si)为每个子词的概率(从语料库中训练得到)
- 流程:
- 对于一个语料库,得到其包含所有的子词,统计所有子词出现的频次,得到子词出现的概率(需要进行穷举,时间复杂度非常高,由此引入维特比(Viterbi)算法解决这个问题,会给出很多条分词路径)
- 对于一个词,可以由不同的子词拼成,由此可计算得到该词出现概率的不同值,由此根据最大的概率,对所有的word进行tokenize
- 对于每一个word,我们选取了一个分词方式,使其概率也就是score最高,那么这些score相加得到一个总分total_score。现在对于语料库中生成的子词进行逐个去除,去除后重新计算其影响的word的score,看total_score下降了多少,选择下降最少的token进行去除,重复这个步骤直到子词数量满足要求
SentencePiece
- 是 Google 研发的一个 用于训练和使用子词(subword)分词器的开源库和工具集,是一个完整的、端到端的分词解决方案,该模型可以代替预训练模型(BERT,XLNET)中词表的作用
- 支持多种subword算法. 支持BPE算法, unigram语言模型算法
- 大多数的无监督分词算法会假设词汇表是无限的(传统), 但是sentencepiece训练分词模型时, 会预先确定词汇表大小, 例如8k, 16k, 32k.
- 纯数据驱动. SentencePiece直接用句子训练tokenizer和detokenizer, 不需要pre-tokenization。使用BPE这类算法进行分词时,在pre-tokenization时,会基于空格进行,这样的间隔信息损失是不可逆的。SentencePiece把输入文本先转为一个unicode字符序列, 这样, 空格也被当作一个标准符号处理. 为了明确的把空格当作一个token处理, 首先会把空格转为元符号U+2581,消除了不同语言分词之间的gap
- 支持子词正则化regularization和BPE dropout,前者会按概率采样一条随机的分词路径而不是指标最优的分词路径,避免模型过拟合某个唯一分词路径;后者则每一个合并操作都有一个被随机跳过的概率,保留选取的两个子词进行下一步
参考资料
- https://kangkang37.github.io/2024/07/29/sentencepiece/